 Direkt zum Inhalt
Direkt zum Inhalt
Blog
Indexing in Elasticsearch with FME
Combining Elasticsearch, FME, AWS and Sharepoint into a dynamic high-performance indexing of a geodata catalogue
Within a major project for Médecins sans Frontières (Doctors without borders, MSF), INSER setup a catalogue to provide maps and other geographical data to MSF’s nearly 40,000 employees as well as to the public. In order to ensure performance and flexibility, we chose to use Elasticsearch as search engine and FME Flow as metadata collector and aggregator.
This technical blog entry describes some of the solutions that we came up with for this project. Illustrating our use of innovative cloud based technologies and architectures.
Documents to be indexed
The pupose of this catalogue is to centralize access for several types of documents and geographical data. Among others:
- Static maps (e.g. PDF)
- Geodata (e.g. KML)
- Satellite imagery
- Web applications with geographical content (GeoApps)
These resources are stored in several formats and places within the organization. We thus needed a tool able to extract metadata from several sources, transform them and then inject them into the index. INSER's expertise with FME allowed us to use it as orchestrator of this process.
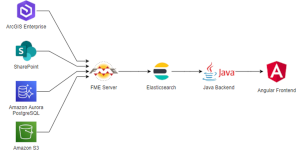
Architecture
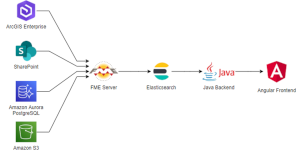
This architecture based on Elasticsearch and FME is flexible enough to easily allow the addition of new data sources to the process. Elasticsearch is also synonym of good performance and comes with numerous search and indexing functionalities.
This article will now dive deeper into some of the required steps of this indexing.
Indexing the elements stored in Sharepoint
Most of the static documents to be indexed are stored in Sharepoint, which is easy to use for the specialists that are creating maps. They use the standard Sharepoint interface to store maps in libraries, each with relevant metadata. Access rights are also defined within SharePoint, so that ultimately the security of the documents is ensured by Microsoft’s tool.
FME Flow connects to this Sharepoint instance through the Graph API, and retrieves the following metadata for each document to be indexed:
- Name, description
- Keywords, theme, countries, (… several business metadata)
- Thumbnails
- List of users that can access the content
- Bounding box
The connection to Sharepoint is done through a WebConnection using the Graph API, directly within the FME workspace.

An HTTPCaller in a loop allows us to get all the elements from a Sharepoint list with a pagination system. The HTTPCaller itself is embedded in a loop to retry requests when they fail, which sometimes happen due to Graph API internal timeouts.

Indexing information stored on Amazon
Some metadata required for the indexation is stored on AWS, either in a S3 bucket or in an Aurora PostgreSQL database. FME accesses the S3 bucket data thanks to the “S3Connector” transformer, then joins them to the relevant documents.

Working with metadata in FME
Once metadata is collected from the various sources, they need to be aggregated into a unique schema that will be fed into Elasticsearch index. Again, FME is the tool of choice to handle and transform this data before it can be used as an index.

Once the data model has been adapted to the index model, the resulting data must be sent to Elasticsearch. The available FME Elasticsearch writer is currently limited to Elasticsearch version 6 and therefore doesn’t meet our requirements.
As the API calls to feed an index are quite esay to handle, we decided to use JSONTemplaters to format a message to be sent through an HTTPCaller in bulk to Elasticsearch. This solution lets us use a more recent version of Elasticsearch.

FME Flow
In order to easily remove the documents that were deleted on Sharepoint from the index, we decided to use a full re-indexation each night. This process is based on 2 indexes:
- A “live” one, which is the one currently used by the catalogue to provide search results.
- An “off” one, which is the one used for re-indexing. This index is then defined as live once the indexing process is completed.
With this system, the indexation process on the “off” index has no incidence on the “live” one, and thus, without service interruption.
An indexation can also be manually launched, for instance if a newly published map needs to appear immediately in the search results. This action must be possible without accessing FME Flow directly, and must be quick. The process we setup for this is based on the user sending an e-mail with specific keywords to the server. Upon reception of this e-mail, the server launches a quick indexation of the documents that were modified within the last 24 hours. This whole process typically takes about 2 minutes.
Elasticsearch and AWS infrastructure
This project is based on Elasticseach version 7.7, fully managed by AWS. Our experience shows that a very small AWS instance (t3.small) is sufficient for this type of usage, generating very reasonable costs. The availability of the production instance is guaranteed by replicating it in three availability zones.
AWS managed services allows to have an Elasticseach instance setup (along with Kibana) in only a few clicks, or better said, a few lines of Terraform code. Later changing versions or instance size is also easy.
Backend and frontend
The backend of the search engine uses the “Java High Level REST Client” of Elastic to communicate with the API and receive results and statistics. Going through a backend was necessary for the security of our index: access to some content is restricted to MSF internal use, or even to individuals. The backend makes sure that only metadata about documents that the user have the right to see are returned.
The Angular frontend sends simplified queries to the backend and retrieves a list of documents. This list comes with statistics allowing to display the number of documents available for each filtering option.
Result
The result on the user side is a fast and practical search engine, empowering the user to easily find the desired document among more than 7000 results.
Technically, this project allowed us to provide a performant solution, making use of the existing document storage and management tools. The “invisible” work done by FME is automated and built on a modern infrastructure, and the result is appreciated by the users. The great flexibility of this system must also be noted, making it very easy ininclude new data sources.
Kontakt
Flavien Rouiller
Chef de projet