 Aller au contenu principal
Aller au contenu principal
Blog
Indexation dans Elasticsearch avec FME
Combiner Elasticsearch, FME, AWS et SharePoint pour une indexation dynamique à hautes performances d’un catalogue de géodonnées
Dans le cadre d’un important projet pour Médecins sans Frontières (MSF), INSER a mis en place un catalogue offrant aux presque 40'000 employés de l’ONG et au public des cartes et autres données géographiques. Afin d’en garantir les performances et la flexibilité, il a été décidé d’utiliser Elasticsearch comme moteur de recherche et FME comme collecteur de métadonnées et agrégateur de documents à indexer.
Ce blog technique décrit quelques-unes des solutions que nous avons mises en œuvre pour ce projet, qui fait appel à des technologies et des architectures résolument innovantes (notamment sur le cloud).
Documents à indexer
Le catalogue a pour but de centraliser l’accès à plusieurs types de documents et données géographiques. Entre autres :
- Des cartes statiques (p.ex. PDF)
- Des géodonnées (p.ex KML)
- Des images satellites
- Des applications géographiques (GeoApps)
Ces documents sont stockés dans divers formats et emplacements au sein de l’organisation. Elasticsearch nécessitait donc en amont un outil capable d’extraire des métadonnées de plusieurs sources, de les transformer puis de les injecter dans l’index. L’expertise d’INSER dans l’utilisation de FME a permis de l’utiliser comme orchestrateur de ce processus.
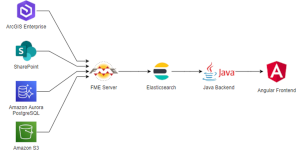
Architecture
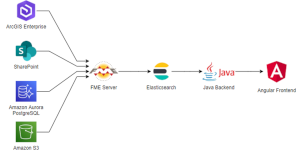
Figure 1 Architecture de notre solution de moteur de recherche
Cette architecture basée sur Elasticsearch et FME Flow garantit une souplesse qui permet par exemple d’ajouter facilement de nouvelles sources de données. Elasticsearch est également garant de performance et propose de nombreuses fonctionnalités d’indexation et de recherche.
Ci-après, nous entrons plus en détail sur certaines des étapes de cette indexation.
Indexation des documents de stockés dans SharePoint
La plupart des documents statiques de cette infrastructure sont stockés sur SharePoint, ce qui permet une gestion facile pour les spécialistes qui créent ces cartes. Chaque carte y est stockée avec ses métadonnées, dans un dossier approprié. C’est également dans SharePoint que les droits d’accès à chaque document sont définis.
FME Flow se connecte à cette infrastructure SharePoint au moyen de l’API Microsoft Graph et, pour chaque document à indexer, récupère les métadonnées suivantes :
- Nom, Description
- Mots-clés, Thèmes, Pays concernés, …
- Images d’aperçu (thumbnails)
- Liste des utilisateurs ayant le droit de voir le contenu
- Bounding box
La connexion à SharePoint se fait avec une WebConnection via l’API Graph, réalisée dans le Workspace FME lui-même.

Figure 2 Aperçu de la WebConnection à l'API Microsoft Graph
Puis un HTTPCaller dans une boucle permet de récupérer tous les éléments d’une liste SharePoint avec un système de pagination. Le HTTPCaller est lui-même inclus dans une boucle pour retenter la requête lorsque l’API Graph rencontre un timeout.

Figure 3 Cette boucle permet de passer à travers toutes les pages que renvoie l'API Graph.
Indexation des documents stockés sur Amazon
Plusieurs informations nécessaires à l’indexation sont stockées sur AWS, soit dans un bucket S3, soit dans une base de données Aurora PostgreSQL. Dans le cas du bucket S3, FME y accède au moyen d’un transformer « S3Connector » puis les lie aux documents concernés.

Figure 4 Le S3Connector permet de récupérer les métadonnées des fichiers stockés sur un S3 d’AWS.
Exploitation des métadonnées dans FME
Une fois les métadonnées récupérées dans les différentes sources, elles doivent être regroupées dans un schéma unique afin de créer l’index Elasticsearch. Ici encore, c’est FME qui se charge de la mise en relation de ces informations et de leur préparation en vue de leur stockage.

Figure 5 Triage par type de contenu et application de règles métier pour chacun.
Une fois le schéma des données adapté à celui de l’index, les métadonnées sont stockées dans Elasticsearch. Il existe un writer FME Elasticsearch, mais pour l’instant limité à la version 6 d’Elasticsearch.
Étant donné que les appels à l’API ne sont pas trop complexes, nous utilisons des JSONTemplaters pour formater le message et un HTTPCaller pour l’envoyer par blocs (bulk).

Figure 6 Étape de remplissage de l’index, avec détail du JSON Templater. Le custom transformer « AggregateByGroups » permet de grouper les requêtes par groupe pour optimiser l’utilisation de l’API. Typiquement pour des documents lourds avec thumbnails, nous les groupons par 10. L’appel http à l’API elsaticsearch est faite à l’intérieur d’un custom transformer (ElasticRetry) permettant de réessayer l’appel lorsqu’une première tentative rencontre un problème.
FME Flow
Afin de supprimer facilement de l’index les éléments qui l’ont été de SharePoint, nous avons opté pour la solution d’une ré-indexation complète chaque nuit. Concrètement, deux index sont créés:
- Un « live » qui est celui utilisé en ce moment par le portail pour fournir des résultats de recherche
- Un « off » qui est celui sur lequel la ré-indexation a lieu. Cet index est défini comme « live » lorsque l’indexation nocturne est terminée.
Ce système permet de travailler sur l’index « off » sans influencer l’index « live », et donc sans interruption de service.
Une indexation peut également être appelée manuellement pour une mise à jour rapide de l’index. C’est le cas si une carte récemment créée doit apparaître immédiatement dans les résultats des recherches. Cette action doit être possible sans devoir se connecter à FME Flow. Nous avons donc mis en place une procédure selon laquelle l’utilisateur envoie un E-Mail contenant certains mots-clés au Serveur. La réception de cet E-Mail déclenche le processus d’indexation rapide, d’une durée inférieure à 2minutes.
Elasticsearch et infrastructure AWS
Ce projet est basé sur la version 7.7 d’Elasticsearch, gérée entièrement par AWS. Nous constatons que pour l’usage qui en est fait, une très petite instance AWS (t3.small) est suffisante et les coûts donc modérés.
La gestion par AWS permet d’avoir une instance Elasticsearch et Kibana prête en quelques clics. Les changements de version ou de puissance sont aussi faciles.
Backend et frontend
Le backend utilise le “Java High Level REST Client” d’Elastic pour communiquer avec l’API et obtenir les résultats de recherche et des statistiques. Passer par le backend est nécessaire pour la sécurité de notre index. En effet, l’accès à certains contenus est restreint aux utilisateurs connectés, voir à certains utilisateurs en particulier. Le backend s’assure que seules les métadonnées concernant les documents auxquels l’utilisateur a droit lui sont renvoyées.
Le frontend en Angular passe des requêtes simplifiées au backend et reçoit une liste de documents en retour. Cette liste est accompagnée de statistiques permettant par exemple d’afficher le nombre de documents disponibles par catégorie de filtre.
Résultat
Le résultat, côté utilisateur, est un moteur de recherche fluide et pratique, capable de trouver facilement et rapidement le document recherché parmi environ 7000 résultats.
Au niveau technique, ce projet nous a permis de proposer une solution performante pour l’utilisateur, utilisant les outils existants de stockage et de gestion des documents. Elle présente aussi une grande souplesse d’adaptation permettant d’ajouter de nouvelles sources de données. Ce travail « de l’ombre » automatisé, pris en charge par FME et construit sur une architecture moderne est particulièrement appréciée par les utilisateurs.
Contact
Flavien Rouiller
Chef de projet